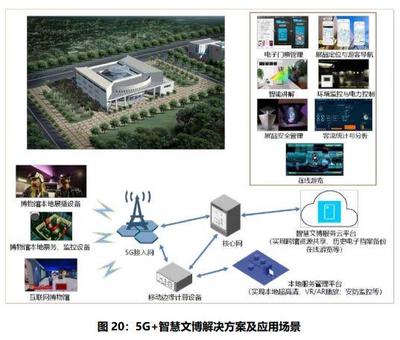
隨著全球5G網絡的規模化部署,其發展已邁入一個全新的階段。過去幾年,業界焦點主要集中在通信技術本身的突破,如更高的頻譜效率、更低的時延和更大的連接密度。當前5G發展的新方向正清晰地表明,其價值遠不止于通信技術的單點進步,而在于如何作為一項基礎性、使能性技術,深度融合并賦能千行百業,構建一個泛在、智能、高效的服務體系。這一演進方向正將5G從純粹的“通信管道”重塑為“智能社會的數字底座”。
1. 從連接人到連接萬物,拓展應用場景邊界
5G發展的首要新方向是應用場景的深度和廣度拓展。初期5G主要服務于增強型移動寬帶(eMBB),提升個人消費者的移動互聯網體驗。如今,其重心正快速向海量機器類通信(mMTC)和超高可靠低時延通信(uRLLC)兩大場景傾斜。這意味著5G網絡正從連接“人”全面轉向連接“物”與“產業”。在工業互聯網領域,5G正成為工廠自動化的神經系統,支撐AGV調度、遠程控制、機器視覺質檢等高精度應用。在智慧城市中,5G賦能海量物聯網設備,實現智能交通、環境監測、安防聯動的實時響應。在醫療健康領域,5G支持的遠程手術、急救車實時數據傳輸正打破醫療資源的時空限制。這些應用場景的爆發,標志著5G的價值正從“技術指標”轉化為切實的“社會生產效率與服務質量提升”。
2. 網絡即服務:通信技術與行業需求的深度融合
“5G通信技術服務”的內涵正在發生深刻變化。傳統通信服務模式相對單一,而5G時代則強調“網絡即服務”。通過引入網絡切片、邊緣計算、能力開放等關鍵技術,運營商能夠為不同行業客戶量身定制虛擬化、隔離性、功能各異的邏輯專網。例如,為自動駕駛提供超高可靠低時延的網絡切片,為媒體直播提供大帶寬且保障服務質量的專用通道,為智慧園區提供數據本地化處理的邊緣計算平臺。這種深度融合要求5G技術服務從標準化的管道提供,轉變為深入理解行業流程、痛點,并提供端到端解決方案的咨詢服務與集成能力。通信技術服務商需要與垂直行業伙伴緊密合作,共同定義需求、開發應用、部署運維,形成共生共贏的產業生態。
3. 人工智能與5G的共生演進
5G發展的另一關鍵方向是與人工智能的深度耦合。一方面,5G產生、連接的海量數據為AI訓練和推理提供了豐富的“燃料”;另一方面,AI技術又能賦能5G網絡本身,實現智能化的網絡運維、資源調度和性能優化。例如,通過AI算法預測網絡流量潮汐,動態調整網絡資源配置以提升能效;利用AI進行故障根因分析,實現網絡的“自愈”能力。在應用側,5G與AI的結合催生了大量創新服務,如基于5G+AI的實時視頻分析、智能機器人協作、個性化沉浸式體驗等。這種“5G+AI”的雙輪驅動,正在構建一個能夠自我感知、自我學習、自我優化的智能網絡與服務環境。
4. 向6G演進的持續探索與綠色可持續發展
在面向未來的布局中,5G的發展也承載著向下一代通信技術(6G)平滑演進的基礎作用。研究重點開始向更高頻段(如太赫茲)、空天地一體化網絡、通信感知一體化、內生智能等前沿領域延伸。可持續發展成為全球共識,5G網絡自身的綠色節能技術,如基站智能關斷、新型高效功放、可再生能源利用等,也成為重要的發展方向。這不僅是為了降低運營成本,更是履行社會責任,使5G成為支撐數字經濟高質量發展的“綠色引擎”。
總而言之,5G網絡發展的新方向已清晰地從追求單一通信技術指標的突破,轉向構建一個以通信技術為基礎、深度融合人工智能、大數據、云計算,并深度賦能經濟社會數字化轉型的綜合性智能服務體系。其成功與否,將不再僅僅取決于峰值速率,而更在于其與垂直行業結合的深度、所催生新型應用模式的廣度以及最終創造的社會與經濟價值。5G通信技術服務將日益成為一項復雜、系統性的工程,需要產業鏈各方通力協作,共同挖掘這座“金礦”的無限潛能,真正開啟萬物智聯的新時代。